Alpha Zero
Sort:

Oct 9, 2021
0
#2
Leela chess zero, which is modeled on the alpha zero papers, has been set and reset dozens of times. It always ends ups playing the same. The law of large numbers comes into play.

Ah....I suspected it might be that, but it would have been so much more fun if it would develop different strengths and styles. Thanks!
Oct 9, 2021
0
#4
The strengths and styles are developed by tweaking the training algorithm. I believe, though I’m not certain, that you can modify it to value aggressive play or also some other minor things. Honestly, I’m not sure. I just happened to be watching Stockfish vs. Leela in a Twitch chat. They talk about the nerdiest stuff in there that’s way way way over my orange-dyed head, but I do recall someone saying something like that. You can always poke around inside one of those and ask some questions.
Hmm.... Maybe I will come across that in my reading, but while I can see how you would do this for stockfish by giving it different valuations, it would seem much trickier to do it too Alpha Zero because afaik it doesn't really have valuations in some easy spot to manipulate.
I don't think it has, for example, a variable somewhere where it says a knight is worth 3 pawns. You could maybe infer a value by how it plays. I don't think you can set it.
I don't think it has, for example, a variable somewhere where it says a knight is worth 3 pawns. You could maybe infer a value by how it plays. I don't think you can set it.
Oct 9, 2021
0
#6
Like I said, I don’t know. The training goal is “to win.” You could train passivity by saying the first goal is not to lose, and the secondary goal is to win. You can have a training goal to be to win in 40 moves else it’s a loss. This might lead to aggressive play. You make a training goal be “if moves are within x evaluation, use your queen.” There’s lots of manipulation possible.
Oh, so retrain it from scratch with a different goal? Hmm.

Oct 9, 2021
0
#8
Deep Mind did another iteration where they didn't put any rules information into the algorithm and according to the paper, the versions got just as strong as the previous ones that had that information. Though it didn't make any insights on playing style as I recall.

Oct 10, 2021
0
#9
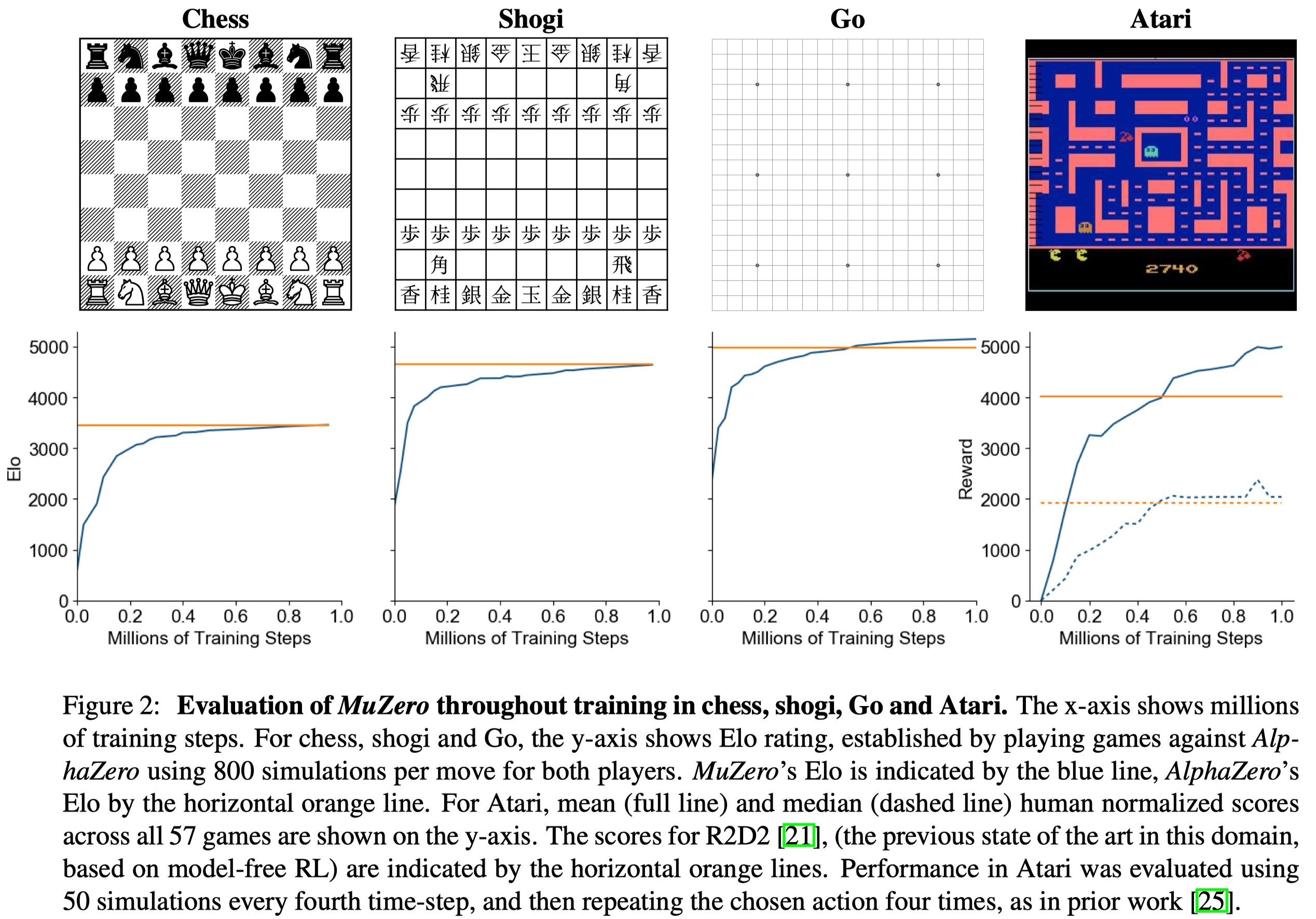
Yes, DeepMind's updated version of AlphaZero was "MuZero".
It mastered chess (and many other games) without knowing the rules of the game at all.
According to the company's research, it "matched" AlphaZero's playing strength after one million self-training steps.
Though some might find it interesting that MuZero's Elo charts showed an upward vertical trend, compared to AlphaZero's Elo line.
In Go and Atari, MuZero's Elo soared past AlphaZero's.
In Shogi, MuZero's Elo seemed to equal AlphaZero's.
In Chess, MuZero showed a very slight upward trend, just barely passing AlphaZero's Elo line at one million training steps.
https://xlnwel.github.io/blog/images/application/MuZero-Figure-2.png
{kind=link}
They seem to have stopped it there, satisfied that MuZero matched AlphaZero's strength. But it seems, if MuZero had been allowed to continue, its chess Elo would have continued to rise at a slow, steady rate.
You can read more about it here:
https://deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules
https://www.nature.com/articles/s41586-020-03051-4.epdf?sharing_token=kTk-xTZpQOF8Ym8nTQK6EdRgN0jAjWel9jnR3ZoTv0PMSWGj38iNIyNOw_ooNp2BvzZ4nIcedo7GEXD7UmLqb0M_V_fop31mMY9VBBLNmGbm0K9jETKkZnJ9SgJ8Rwhp3ySvLuTcUr888puIYbngQ0fiMf45ZGDAQ7fUI66-u7Y%3D
For whatever reason, not knowing the rules of the game led to MuZero finding improvements over AlphaZero.
Oct 10, 2021
0
#10
Google has WAY more important things to do than work on chess. They are currently using the AI to do things to unlock the secrets of protein folding and have made significant progress. This has the potential to help in the fight of many diseases that kill lots of people when proteins fold improperly in the body. Google didn’t work on MuZero because it cared about chess. They used chess as a test to see if there were improvements in its learning algorithm.
Alpha Zero learned by playing itself over millions of games and playing with a certain style that Kasparov described as being similar to himself and Tal, a sacrificial style (is not completely accurate to say Alpha sacrifices, as Garry points out).
So one question that occurs to me early, is it possible Alpha Zero would play with different style if it starts from scratch, or would millions of games always lead to a similar knowledge base?
If you had 2 Alpha Zeroes play each other that had developer independently, would they split exactly 50/50, or is it possible one develops a style superior to the other and dominates?
What do you think?